Looking for Part 1? See: http://www.headenergy.co.uk/2012/10/php-on-ec2-aws-with-multi-a-z-and-multi-region
Looking for Part 2? See: http://www.headenergy.co.uk/2012/10/php-on-ec2-aws-with-multi-a-z-and-multi-region-part-2
Looking for Part 4? See: http://www.headenergy.co.uk/2012/10/php-on-ec2-aws-with-multi-a-z-and-multi-region-part-4
A Quick Intro
In this part of the mini series, we progress into the depths of cloud deployment strategies for the now selected MySQL multi-master replication offering from Codership, Galera. In my previous post I went into detail on why this choice was made, I’d recommend giving it a read if you haven’t!
It is not enough simply to install Galera in the cloud, we need to decide how to leverage the technology within the cloud infrastructure to the best effect for our use case. In this part we’ll discuss 4 of the deployment configurations that are open to us and work out which is best for our needs.
Stack Cluster
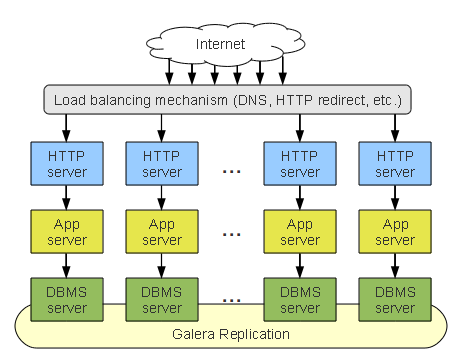 So, lets start simple, in this Stack Cluster we are scaffolding an entire dedicated collection of nodes. To scale we simply add another collection of servers from every layer and connect them together.
So, lets start simple, in this Stack Cluster we are scaffolding an entire dedicated collection of nodes. To scale we simply add another collection of servers from every layer and connect them together.
Pros:
1. It’s exceedingly easy to manage. You also have the option of placing an entire branch (/stack) of software onto one box, making a very elegant deployment strategy.
2. There’s a direct connection from the applications to their database nodes, minimising latency overheads.
Cons
1. Inefficient use of resources for several reasons:
- Overuse: Database servers usually offer more spare capacity than their application layer counterparts, so dedicating a DBMS to a single branch may be overkill.
- Bad resource consolidation: One server with a 7Gb buffer pool is much faster than two servers with 4Gb.
- Increased unproductive overheads: Each server duplicates the work of the others.
2. If a DBMS (Galera) node fails, you’ve lost the entire branch.
3. Increased roll back rate, due to cluster-wide conflicts.
4. Inflexibility: There’s no way here to limit the number of master nodes or perform intelligent load balancing.
DBMS Tier Clustering
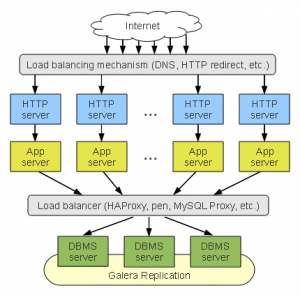 To address the short comings of the Stack Cluster, we could move the DBMS tier away from the application branches and present them as a single virtual server, through the use of a load balancer (Head Energy use HA Proxy, even in the EC2 environment at this stage).
To address the short comings of the Stack Cluster, we could move the DBMS tier away from the application branches and present them as a single virtual server, through the use of a load balancer (Head Energy use HA Proxy, even in the EC2 environment at this stage).
Pros:
1. If one of the DBMS nodes fails, it fails in isolation, as we no longer lose application servers.
2. Improved resource consolidation.
3. Greatly improved flexibility, as we can now dedicate individual DBMS nodes to perform particular roles, and intelligently load balance when required.
Cons:
1. We now have a new single point of failure in the system, the load balancer. If you deploy this configuration, you’ll need to deploy two load balancer nodes, and arrange a failover between them.
2. Increasing management complexity, as we now have to manage the new load balancer, configuring it properly whenever a node fails or joins the cluster.
3. As we’ve introduced a new layer, the load balancers, we’ll have increased the latency for each query too. This can produce a bottleneck in some applications, and certainly the load balancers should be powerful, well equipped nodes.
4. Spreading this configuration over multiple availability zones (or data centres) may reverse all the benefits of resource consolidation, as each database centre will require at least 2 DBMS nodes.
DBMS Tier Clustering (with a distributed load balancer)
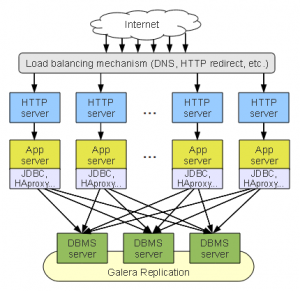 Pros:
Pros:
1. A slight modification to the above configuration. In this modified configuration the load balancer is no longer a single point of failure, indeed it can now scale with the application layer and is unlikely to be a performance bottleneck in and of itself.
2. The latencies on communication between the application and server tiers will be lessened.
Cons:
There are now N load balancers to manage, and reconfigure when nodes leave and enter the pools. This can be somewhat mitigated with software deployment strategies such as Puppet, or using some more advanced load balanced with replication support.
Aggregated Stack Cluster
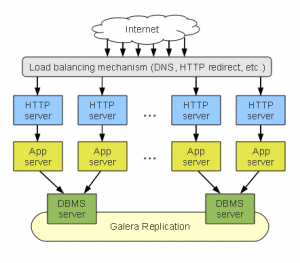 Last, but not least, the aggregated stack cluster is a hybrid approach of the configurations we’ve seen above. It’s tailored to smaller sites which might not need much more than replication across multiple zones / data centres. This is essentially what the previous configuration would look like if we leave one DBMS per stack.
Last, but not least, the aggregated stack cluster is a hybrid approach of the configurations we’ve seen above. It’s tailored to smaller sites which might not need much more than replication across multiple zones / data centres. This is essentially what the previous configuration would look like if we leave one DBMS per stack.
Pros:
1. It improves resource utilization of an entire stack cluster.
2. Maintains the benefits offers in the Stack Cluster configuration of simplicity and direct DBMS connections.
Cons:
1. Not suitable for larger sites due to the single DBMS node for each stack and lack of load balancing.
Our recommendation
We’ve chosen to go with the DBMS tier cluster along with a distributed load balancer as we cross into different regions. This is primarily due to our platform being EC2, as it provides a resilient, reliable and cost effective load balancer, removing the worry of having a single point of failure. This also simplifies the deployment as more database servers are removed or added to the pool, as we only have to configure a single load balancer.
In my next post I’ll show some basic load testing results, and justify the number of Galera boxes I chose to deploy, along with some basic nodes about EC2 and general EC2 thoughts regarding MySQL deployment.