
We’ve written a lot about Concrete5 in Head Energy’s blog, with significant effort spent on documenting our high level AWS architecture for a large Concrete5 Sites. However, going back one step more (and stepping over my hate for the phrase “enterprise ready”, which seems to be synonymous with “bloated, cryptic and slow as hell”), we’re forced to ask today: is Concrete5 really an “enterprise ready” system?
Our project, built on v5.6.1, probably has 50k+ lines of code these days, and one of the ever increasing worries during our development has been that of slow page loads. We’re seeing un-cached page load times creep up from their early renders of 1s-2s to a current average of 4s-6s, and it’s getting worse linearly with the complexity of the page. The linearity suggests we’re simply introducing a greater workload and have only ourselves to blame, but after just a few minutes of looking for high load anywhere in our architecture I was at a loss, until I did the bog standard check for database queries.
The number of queries Concrete5 generates when using it’s own API is utterly staggering a landing page deemed moderately complex generated precisely 6882 queries to render from start to finish.
The number of queries Concrete5 generates when using it’s own API is utterly staggering a landing page deemed moderately complex generated precisely 6882 queries to render from start to finish, and the agent wasn’t even logged in! This isn’t a problem on a developers machine, where the latency between their MySQL layer and the web server is effectively 0. When we add a 0.5ms latency (think AWS load balancers, traffic managers or just networking!) the delay from latency balloons to 3.441 seconds in additional page load time.
What’s worse is we’ve taken some significant steps to reduce the number of Page List blocks in use on Concrete5, simply because we already knew it was ridiculously heavy on the database with only a few dozen pages in play. We wrote an override which completed what Concrete5 was achieving in the Page List from hundreds of statements in just one (without permissions however, but more on that in a moment).
Finding out the number of database queries Concrete5 generates per page
Concrete5 comes packing the adodb abstraction layer, which has a nice inbuilt function to log all database queries into a table. To make use of it you’ll probably have to create the logging table manually (we did) the statement for which is:
CREATE TABLE IF NOT EXISTS `adodb_logsql` ( `created` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', `sql0` varchar(250) NOT NULL DEFAULT '', `sql1` text NOT NULL, `params` text NOT NULL, `tracer` text NOT NULL, `timer` decimal(16,6) NOT NULL DEFAULT '0.000000' )
Once created switching on the logging function within Concrete5 is as simple as calling
Database::setLogging(true);
You can use this around particular operations in your code, just to take a peek, or just as a quick solution throw it right at the bottom of:
concrete/core/libraries/database.php
Now, every time you reload a page in Concrete5, the adodb_logsql table will fill up with the queries generated to make that page load. We’ve confirmed our suspicions that the Page::getBy* methods are kicking out a significant chunk of our statements, and plan to remove as many of these as possible over the next few days in place of customized SQL.
Is Concrete5 Enterprise Ready?
If your environment is very cache friendly, or you don’t have too many pages (arbitrarily e.g. 250+), then yes you’ll love the entire journey without the need to get very technical. If this isn’t the case, then you’ll quickly need a set of proficient developers who are happy to replace chunks of Concrete5′s native functionality with more efficient alternative routines (namely less SQL statements!).
That said, we’re still hugely enamoured with our choice of platform, and do not believe any other system offers a better ratio of user friendliness, flexibility, scalability and out of the box CMS features, at least not yet.
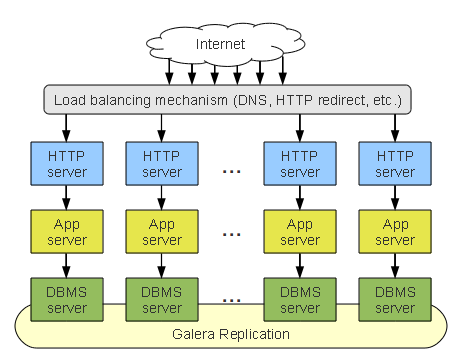 So, lets start simple, in this Stack Cluster we are scaffolding an entire dedicated collection of nodes. To scale we simply add another collection of servers from every layer and connect them together.
So, lets start simple, in this Stack Cluster we are scaffolding an entire dedicated collection of nodes. To scale we simply add another collection of servers from every layer and connect them together.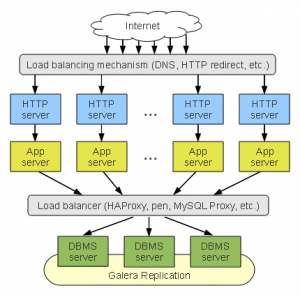 To address the short comings of the Stack Cluster, we could move the DBMS tier away from the application branches and present them as a single virtual server, through the use of a load balancer (Head Energy use HA Proxy, even in the EC2 environment at this stage).
To address the short comings of the Stack Cluster, we could move the DBMS tier away from the application branches and present them as a single virtual server, through the use of a load balancer (Head Energy use HA Proxy, even in the EC2 environment at this stage).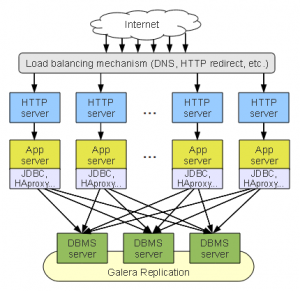 Pros:
Pros: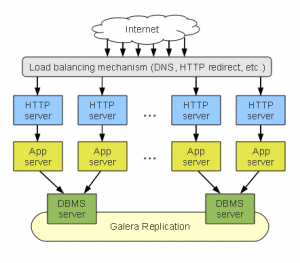 Last, but not least, the aggregated stack cluster is a hybrid approach of the configurations we’ve seen above. It’s tailored to smaller sites which might not need much more than replication across multiple zones / data centres. This is essentially what the previous configuration would look like if we leave one DBMS per stack.
Last, but not least, the aggregated stack cluster is a hybrid approach of the configurations we’ve seen above. It’s tailored to smaller sites which might not need much more than replication across multiple zones / data centres. This is essentially what the previous configuration would look like if we leave one DBMS per stack.

