
A Quick Intro
There seems to be quite an appetite for this mini-series on the web, so I’ve sped up the writing process a little in the hope of mind dumping what remains of this content before people lose interest.
In my recent posts I’ve discussed the problems of deploying a popular PHP CMS into the AWS cloud hosting platform, the options one might consider in spreading out the database tier in a non-split environment, and finally how we can best leverage our choice of Galera. If you’re buying what we’re selling here, then you’ve got a multi-master set up, with good resiliency to zone, and even region, failure at the database tier. This post will go into more detail regarding our chosen configuration, including some performance notes so we’re better informed of the power of this deployment.
Our Configuration Choice
For those that don’t recall, part 3 of this mini-series handled the different configurations open to us with regard to Galera. Our recommendation reads:
We’ve chosen to go with the DBMS tier cluster along with a distributed load balancer as we cross into different regions. This is primarily due to our platform being EC2, as it provides a resilient, reliable and cost effective load balancer, removing the worry of having a single point of failure. This also simplifies the deployment as more database servers are removed or added to the pool, as we only have to configure a single load balancer.
In reality, we don’t know what our load will be precisely, so we’re going to go with the straightforward minimum 3 production servers for our tests, along with 1 additional server on standby.
Benchmark tests (using sysbench with 15 tables of 2m records each) show the potential Transactions Per Second (TPS) and latency for a Galera cluster on EC2; m1.large instances (7.5Gb RAM, 2 cores). This shows that a 4 node Galera cluster on EC2 can support almost 1000 transactions per second with 110 concurrent users. With no serious degredation of latency. As a comparison, the native NDB cluster benchmark with the same tables saw latency increase to in excess of 600ms for the same 110 user concurrency. The following images show our results in greater detail:
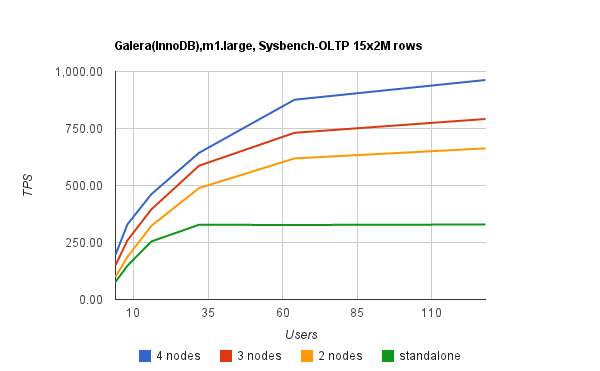
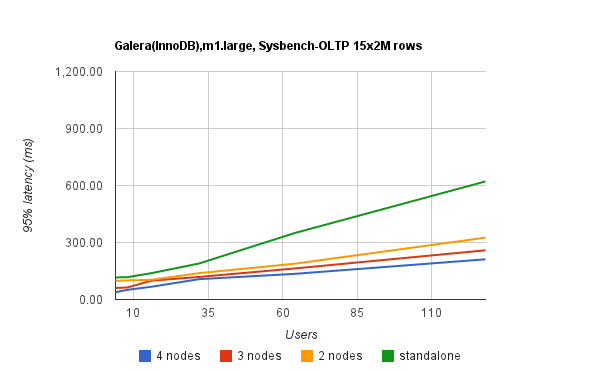
As the system scales out it may well prove more efficient to move to the aggregated stack cluster (discussed in the previous post). After examining the the stats and performance of Concrete5, we’re confidant that a single database server can serve multiple application stacks. Particularly poignant – given we know we’ve got a ceiling on the number of Galera nodes available to us in our cluster – we can easily scale out many application stacks radio before we focus on scaling MySQL.
The Initial EC2 Configuration
Based on our assessment above, and assuming use of EC2, we’re going to use the following configuration:
- 1 VNC per site (though this is mandated by AWS)
- 3 Large EC2 instances running Galera, with an extra on standby.
- 6 EBS volumes using RAID0 for the data files and one EBS for the server application and O/S.
In future posts I’ll outline the full deployment structure we’ve chosen, including GlusterFS, a NAT entry point node, a DNS pair, Load balancer(s) (HA Proxy), underpinned by Puppet for very flexible deployments. We’re also likely to use either ZXTM (in conjunction with the Amazon AWS API) or Elastic Load Balancing to achieve automatic scaling in our deployment.







Comments are closed.